
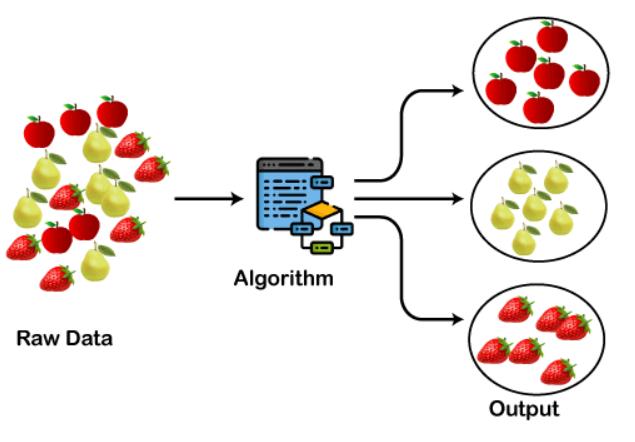
Clustering ek technique hai jo data ko groups mein divide krte hai, jise clusters kehte hain. Ye groups similar items ko ek saath rakhte hain. Matlab, jo data points ek jese hai, unko ek cluster mei daal diya jata hai. Yeh unsupervised learning ka part hota hai, matlab yeh technique bina labeled data ke kaam karti hai.
Structure: Clustering ka structure simple hai. First, data ko analyze karte hain then uske basis pe clusters banate hai. Yeh clusters data ke similarity ya density ke base pe bante hai. Hierarchical clustering mein clusters ko tree-like structure mein arrange karte hai, jise dendrogram kehte hai. Partitioning clustering mein data ko pre-defined clusters mein break kiya jata hai.
Techniques:
K-Means Clustering:
Yeh ek popular partitioning technique hai jisme data points ko predefined "k" clusters mein divide kiya jata hai. Har cluster ka ek centroid hota hai, aur data points ko unke nearest centroid ke according cluster mein assign kiya jata hai. Yeh iterative process hota hai jo tab tak chalta hai jab tak clusters stable na ho jayein.
Steps:
·
Hierarchical Clustering:
Yeh technique data ko layers mein divide karti hai, ek tree-like structure banati hai jise dendrogram kehte hain. Do tarike hote hain:
1. Agglomerative Clustering (Bottom-up): Pehle har data point ko apna ek cluster banaya jata hai, aur phir close clusters ko merge karte jate hain.
2. Divisive Clustering (Top-down): Sabse pehle ek single cluster banate hain jo poore data ko represent karta hai, phir isse smaller clusters mein divide karte hain.
Steps:
Density-Based Clustering:
Ismein clusters un regions mein bante hain jahan data points ki density zyada hoti hai. Is technique ka fayda yeh hai ki yeh noise ya outliers ko ignore kar sakti hai, jo large aur scattered data ke liye ideal hota hai.
Steps:
Advantages: Its irregular shapes ke clusters ko handle karne mein kaafi effective hoti hai, unlike K-Means jo spherical clusters ko prefer karta hai.
Gaussian Mixture Models (GMM):
Yeh probabilistic model use karta hai, jisme data ko multiple Gaussian distributions ke mix ke roop mein model kiya jata hai. Har data point ko uss cluster mein assign kiya jata hai jisme uska probability score highest hota hai. Yeh technique tab useful hoti hai jab clusters overlap karte ho ya jab data ko soft clustering (jahan ek data point multiple clusters mein belong kar sakta hai) ke through model karna ho.
Steps:
Advantages: Overlapping clusters ko identify karna ho toh GMM zyada effective hota hai, jab K-Means fail hota hai.
Advantages:
Disadvantages:
Applications:
Conclusion: Clustering ek powerful tool hai data analysis ke liye. Yeh alag-alag techniques use karke data ke hidden insights search krne mein madad karta hai. Har technique ka apna ek unique approach hota hai, aur data ki nature ke hisaab se best technique choose karna chahiye. Like K-Means large datasets ke liye acha hai, density base noisy datasets ke liye aur GMM jab data ko distributions mein fit karna ho. Isliye, clustering techniques ko samajhna aur sahi way se apply karna data science mein bohot important hai.






















