
Since the invention of computers, people have used the term data to refer to computer information, and this information was either transmitted or stored. But that is not the only data definition; there exist other types of data as well. So, what is the data? Data can be texts or numbers written on papers, or it can be bytes and bits inside the memory of electronic devices, or it could be facts that are stored inside a person’s mind. Now, if we talk about data mainly in the field of science, then the answer to “what is data” will be that data is different types of information that usually is formatted in a particular manner or the quantities, characters, or symbols on which operations are performed by a computer, which may be stored and transmitted in the form of electrical signals and recorded on magnetic, optical, or mechanical recording media.
Then comes the question “what is Big Data”? As per the definition on the Oracle website, “The definition of big data is data that contains greater variety, arriving in increasing volumes and with more velocity. This is also known as the three Vs, Volume, Velocity, Variety. Put simply, big data is larger, more complex data sets, especially from new data sources. These data sets are so voluminous that traditional data processing software just can’t manage them. But these massive volumes of data can be used to address business problems you wouldn’t have been able to tackle before.” Size is the first, and at times, the only dimension that leaps out at the mention of big data.
Now that I have addressed the elephant in the room, lets understand what are the different types of data.
Following are the types of Big Data:
Structured
Any data that can be stored, accessed and processed in the form of fixed format is termed as a ‘structured’ data. Over the period of time, talent in computer science has achieved greater success in developing techniques for working with such kind of data (where the format is well known in advance) and also deriving value out of it. However, nowadays, we are foreseeing issues when a size of such data grows to a huge extent, typical sizes are being in the rage of multiple zettabytes.
Examples Of Structured Data
An ‘Employee’ table in a database is an example of Structured Data
|
Employee_ID |
Employee_Name |
Gender |
Department |
Salary_In_lacs |
|
2365 |
Rajesh Kulkarni |
Male |
Finance |
650000 |
|
3398 |
Pratibha Joshi |
Female |
Admin |
650000 |
|
7465 |
Shushil Roy |
Male |
Admin |
500000 |
|
7500 |
Shubhojit Das |
Male |
Finance |
500000 |
|
7699 |
Priya Sane |
Female |
Finance |
550000 |
Unstructured
Any data with unknown form or the structure is classified as unstructured data. In addition to the size being huge, un-structured data poses multiple challenges in terms of its processing for deriving value out of it. A typical example of unstructured data is a heterogeneous data source containing a combination of simple text files, images, videos etc. Now day organizations have wealth of data available with them but unfortunately, they don’t know how to derive value out of it since this data is in its raw form or unstructured format.
Examples Of Un-Structured Data
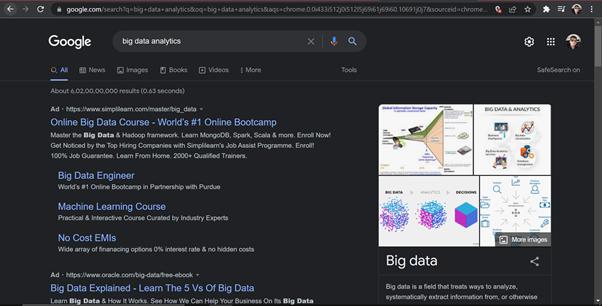
The output returned by ‘Google Search’
Screenshot of Google search
Example Of Un-Structured Data
Semi-structured
Semi-structured data can contain both the forms of data. We can see semi-structured data as a structured in form but it is actually not defined with e.g. a table definition in relational DBMS. Example of semi-structured data is a data represented in an XML file.
Examples Of Semi-Structured Data
Personal data stored in an XML file-
<rec><name>Mathew Thomas</name><sex>Male</sex><age>26</age></rec>
<rec><name>Abrar Khan</name><sex>Male</sex><age>26</age></rec>
<rec><name>Laura Whistler</name><sex>Female</sex><age>29</age></rec>
<rec><name>Jim Halpert Roy</name><sex>Male</sex><age>37</age></rec>
<rec><name>Pam Beasley</name><sex>Female</sex><age>35</age></rec>





















