Definition :
“A well-known machine learning algorithm that makes use of supervised learning techniques is called Random Forest. It works for both classification and regression issues. It is based on ensemble learning, which combines numerous classifiers to address a complicated problem and improve the performance of the model.”
What is Random Forest?
Unsupervised machine learning techniques include random forest. Its accuracy, simplicity, and adaptability make it one of the most popular algorithms. It is very flexible to a variety of data and situations due to its nonlinear structure, its ability to be utilized for classification and regression tasks, and both of these attributes.
By 1995, Tin Kam Ho had coined the phrase "random decision forest." Ho created a formula to make predictions based on random data. Then, in 2006, Leo Breiman and Adele Cutler developed the technique and produced the random forests that are still in use today. The math and science underlying this technique are therefore still rather young.
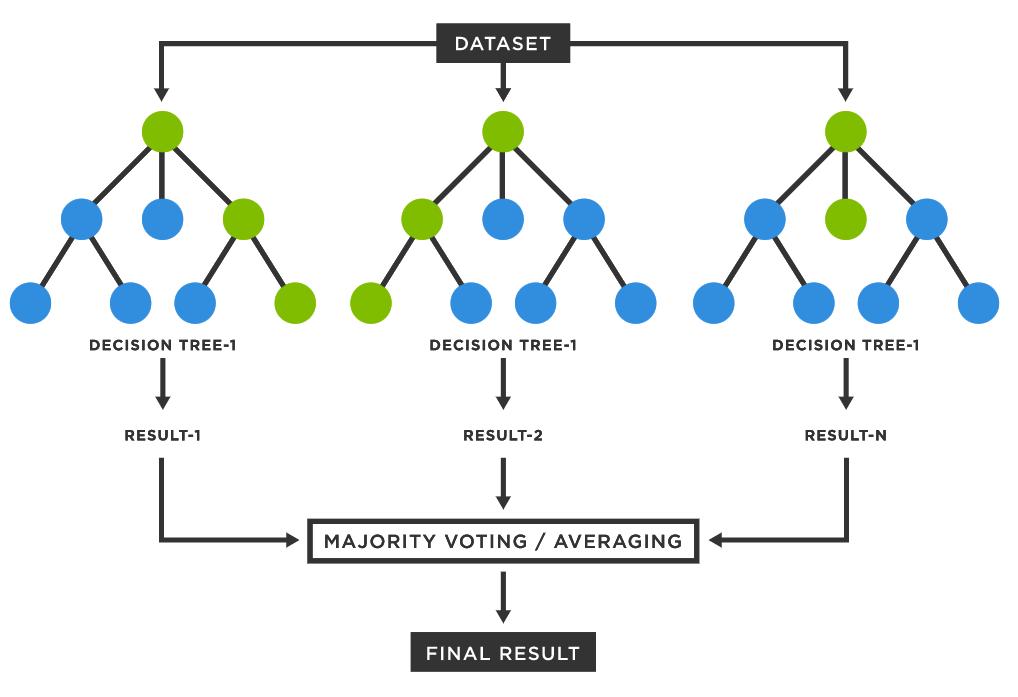
A forest of decision trees is what gives it the name "forest." The information from various trees is then combined to get the most precise forecasts. A forest ensures a more accurate conclusion with a greater number of groups and decisions, whereas a single decision tree only allows for one outcome and a limited range of groups. By selecting the best feature from a randomly selected group of features, it also has the added advantage of randomizing the model. The net result of these advantages is a model that many data scientists find to have a wide range of diversity.